
앞 게시물에 사용한 Dense는 fully-connected(FC) layer로써 1차원 배열 데이터로 한정됩니다.
그러나 컬러 사진 1장은 3차원 배열 데이터이기 때문에 FC신경망을 이용하여 사진을 학습시키기 위해서는
3차원 데이터를 1차원 데이터로 평면화 시켜서 학습 시켜줘야합니다.
따라서 신경망이 추출 및 학습시에 굉장히 비효율적이고 정확도를 높이는 데 한계가 있을 수 밖에 없습니다.
이미지 공간 정보를 유지한 상태에서 학습을 시킬 수 있는 모델이 바로 CNN(Convolutional Neural Network)입니다.

Convolution 신경망은 이미지가 가지는 특성이 고려되어 설계된 신경망이므로 영상 처리에 주로 사용됩니다.
CNN의 구조는 위의 그림과 같이 그림에 한 필터가 순회적으로 돌며 합성곱을 계산하여 그 결과로 하나의
피쳐맵을 형성합니다.
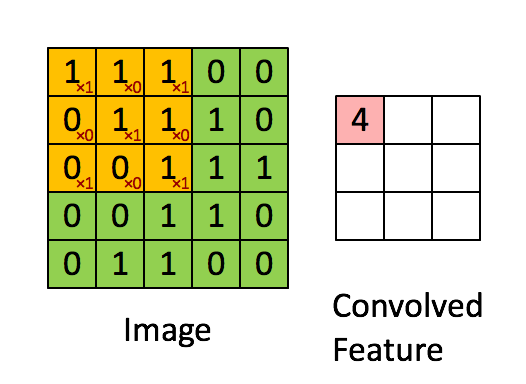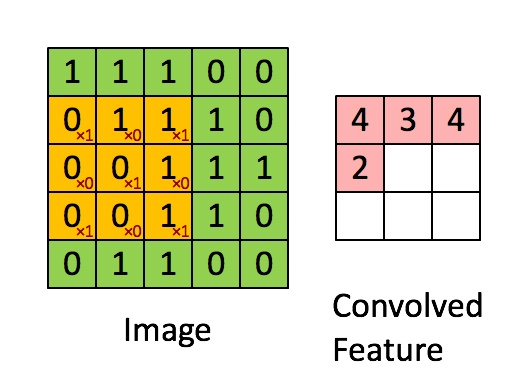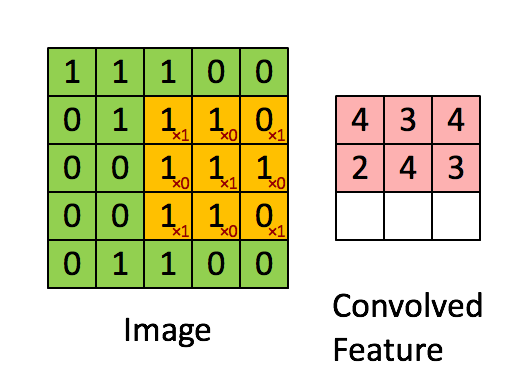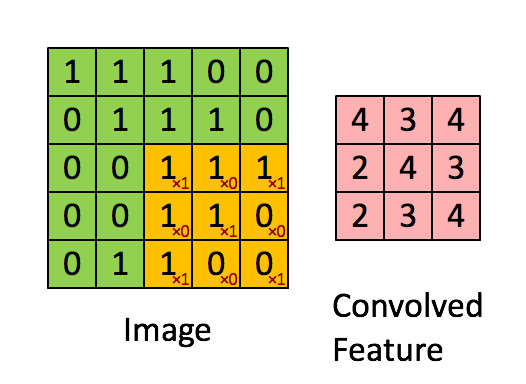
합성곱을 함으로써 얻게되는 효과는 아래 사진을 보면 쉽게 이해할 수 있습니다.
왼쪽에 숫자 30으로 이루어진 부분을 따라 그려보면 오른쪽의 그림과 거의 비슷한 모양입니다.
사진이 픽셀 데이터로 구성되어있음을 알 수 있습니다.

Polling 은 컨볼루션 레이어의 출력 이미지에서 합성곱을 계산하여 주요값을 뽑아 크기가 작게 출력하여 만듭니다.
아래의 그림을 보시면 4X4의 map에서 2X2 네칸으로 나눌수 있는데 각 칸의 최고 크기의 숫자를 뽑아서 2X2로 resize한 모습입니다.
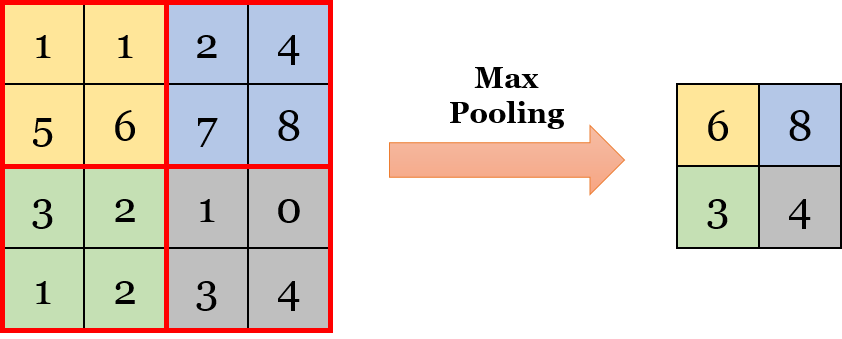
본래 신경망은 인간의 신경계를 모사한 것인데 뉴런이 큰 신호에 반응하는 것과 유사합니다.
주요값을 뽑아서 resize시키는 max pooling을 거치면 노이즈 감소, 속도 증가, 영상의 분별력 강화등이 이점이 있습니다.
CNN은 overfitting(너무 학습시켜서 오히려 역효과가 발생하는 현상)을 방지할 수 있습니다.
keras에서 CNN을 이용하여 손글씨를 학습해보도록 하겠습니다.
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))컨볼루션 레이어중 Conv2D 레이어를 사용했습니다. 영상인식에 주로 사용되는 레이어입니다.
Conv2D(32, (3,3) , activation ='relu', input_shape=(28,28,1))
32 : 컨볼루션 필터의 수 입니다.
(3,3) : 컨볼루션 커널의 행열입니다.
활성화 함수로는 'relu'를 이용하였습니다.
input_shape=(28,28,1) : 입력값을 28X28 로 주었고, 흑백 사진인 채널1을 사용하였습니다.
MaxPooling2D(2,2) : 축소 비율을 2,2로 지정하였습니다.
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))Convolution과 MaxPooling 과정을 거쳤으니 주요 특징들만 추출 되었을 것입니다.
추출된 주요 특징은 전결합층(Fully-connected)에 전달되어 학습됩니다. 위의 컨볼루션과 풀링의 과정은 2차원 자료를 다루지만 전결합층에 전달하기 위해선 1차원 자료로 바꿔줘야 합니다. Flatten의 원리는 아래의 사진과 같은 느낌입니다.

model.summary()
model.summary()를 이용하여 출력타입을 확인할 수있는데
conv2d_9 (Conv2D) (None,3,3,64) 에서
flatten_3 (Flatten) (None,576) 으로 바뀌었습니다.
즉 flatten 과정을 거쳐 3X3X64 = 576576으로 평탄화 되어 두개의 Dense층으로 들어갔습니다.
from keras.datasets import mnist
from keras.utils import to_categorical
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1))
test_images = test_images.astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
학습할 데이터와 테스트할 데이터 셋을 설정했습니다.
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=5, batch_size=64)
test_loss, test_acc = model.evaluate(test_images, test_labels)모델을 컴파일 설정 후 테스트를 진행하는 과정입니다.

CNN을 이용한 손글씨셋 인식의 정확도는 0.9929정도 나왔습니다.
참고사이트
----------------------------------------------------------------------------------------------------------------------------------
딥러닝 알고리즘의 대세, 컨볼루션 신경망(convolutional neural network, CNN)
인공지능이 핫하다. 핫한지 벌써 오래다. 인공지능이 발전하게 된 계기는 크게 세가지로 볼 수 있다. 딥러닝 알고리즘의 발전. 데이터량의 폭발적인 증가. GPU의 발전. 딥러닝 알고리즘은 가장 간단한 피드포워드..
bskyvision.com
CNN을 이해해보자. fully connected layer는 뭔가
*본 글은 개인 공부를 위해 복사 및 인용한 글들의 출처를 명시하고 적는 글입니다. 무단 도용 및 인용으로 인한 책임은 지지 않습니다. 요즘 귀차니즘에 빠졌어요. 펜으로 적기 귀찮아서 제가 찾아본 내용들은 시간 순으로 쭉 정리해서 블로깅 하려고 합니다. 머리에서 필요하다고 생각하는 거를 바로바로 찾는 과정이라 많이 두서가 없을 수 있습니다 . 존댓…
sonofgodcom.wordpress.com
AhnSungJoo - Overview
Machine Learning & Blockchain & Quant . AhnSungJoo has 34 repositories available. Follow their code on GitHub.
github.com
'AI > Keras' 카테고리의 다른 글
| [Keras] Faster R-CNN를 이용한 Video Object Detection (Not Real-time) (0) | 2020.04.14 |
|---|---|
| [Keras] Anaconda를 이용한 Faster R-CNN 세팅 및 예제 실행 (22) | 2020.04.03 |
| [Keras] Mask R-CNN 환경 구성 및 Object Detection 예제 실행 (2) | 2020.04.01 |
| [Keras] MNIST 손글씨 데이터 셋을 이용한 Keras 기초 과정 알아보기 (0) | 2020.03.26 |

