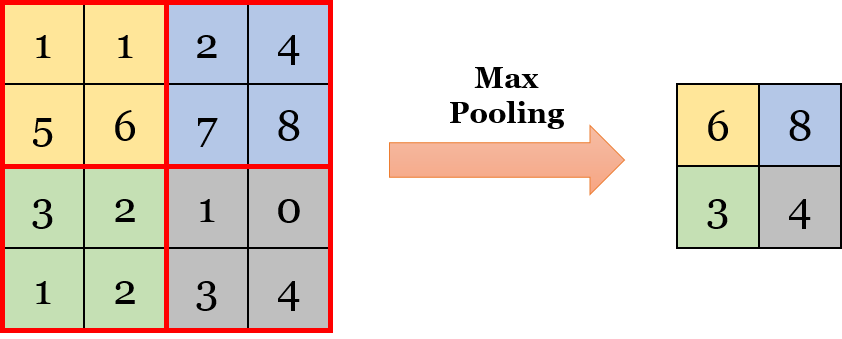
저의 그래픽카드는 GTX 1050 Ti 이기 때문에 제 환경에 맞춰 진행하였습니다.
*[실행 환경]
Visual studio 2015
CUDA 10.1
cuDNN 7.6.3
OpenCV 4.0.1
기준으로 설치 튜토리얼을 진행하고, Visual Studio 가 설치되있다는 가정하에 진행하겠습니다.
목차
1. CUDA, cudnn 설치
2. OpenCV 설치
3. darknet 설치 및 환경 세팅
4. 간단한 예제 실행
1. CUDA 10.1 , cuDNN v7.6.3 설치
****** 주의사항 ******
참고: 저는 그래픽카드가 GTX 1050 Ti 이기 때문에 CUDA 10.1 버전을 사용할 수 있습니다.
CUDA는 버전이 다양한데, Compute capability에 따라 설치할 수 있는 버전이 있습니다.
꼭 본인에 Compute capability에 맞는 CUDA 버전을 설치해주셔야 합니다.
CUDA 10.1 버전은 Compute capability 3.0~7.5 가 지원됩니다.
- CUDA SDK 1.0 support for compute capability 1.0 – 1.1 (Tesla)
- CUDA SDK 1.1 support for compute capability 1.0 – 1.1+x (Tesla)
- CUDA SDK 2.0 support for compute capability 1.0 – 1.1+x (Tesla)
- CUDA SDK 2.1 – 2.3.1 support for compute capability 1.0 – 1.3 (Tesla)
- CUDA SDK 3.0 – 3.1 support for compute capability 1.0 – 2.0 (Tesla, Fermi)
- CUDA SDK 3.2 support for compute capability 1.0 – 2.1 (Tesla, Fermi)
- CUDA SDK 4.0 – 4.2 support for compute capability 1.0 – 2.1+x (Tesla, Fermi, more?).
- CUDA SDK 5.0 – 5.5 support for compute capability 1.0 – 3.5 (Tesla, Fermi, Kepler).
- CUDA SDK 6.0 support for compute capability 1.0 – 3.5 (Tesla, Fermi, Kepler).
- CUDA SDK 6.5 support for compute capability 1.1 – 5.x (Tesla, Fermi, Kepler, Maxwell). Last version with support for compute capability 1.x (Tesla)
- CUDA SDK 7.0 – 7.5 support for compute capability 2.0 – 5.x (Fermi, Kepler, Maxwell)
- CUDA SDK 8.0 support for compute capability 2.0 – 6.x (Fermi, Kepler, Maxwell, Pascal). Last version with support for compute capability 2.x (Fermi) (Pascal GTX 1070Ti Not Support)
- CUDA SDK 9.0 – 9.2 support for compute capability 3.0 – 7.2 (Kepler, Maxwell, Pascal, Volta) (Pascal GTX 1070Ti Not Support CUDA SDK 9.0 and support CUDA SDK 9.2)
- CUDA SDK 10.0 – 10.2 support for compute capability 3.0 – 7.5 (Kepler, Maxwell, Pascal, Volta, Turing). Last version with support for compute capability 3.x (Kepler). 10.2 is the last official release for macOS, as support will not be available for macOS in newer releases. (저는 Compute capability가 6.1 이므로 10.1 버전을 사용할 수 있습니다.)
- CUDA SDK 11.0 – support for compute capability 5.2 - 8.0 (Maxwell, Pascal, Volta, Turing, Ampere)
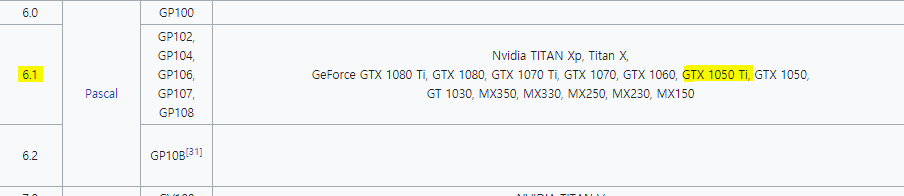
자세한 내용은 아래 사이트를 참조하시면 됩니다.
https://en.wikipedia.org/wiki/CUDA
CUDA - Wikipedia
CUDA (Compute Unified Device Architecture) is a parallel computing platform and application programming interface (API) model created by Nvidia.[1] It allows software developers and software engineers to use a CUDA-enabled graphics processing unit (GPU) fo
en.wikipedia.org
https://developer.nvidia.com/cuda-toolkit-archive
CUDA Toolkit Archive
Previous releases of the CUDA Toolkit, GPU Computing SDK, documentation and developer drivers can be found using the links below. Please select the release you want from the list below, and be sure to check www.nvidia.com/drivers for more recent production
developer.nvidia.com
위의 페이지에 들어가서 CUDA Toolkit 10.1 [Feb 2019] 버전을 클릭해줍니다.

클릭을 하시고 들어가시면 아래와 같이 local 로 설정하여 다운받아서 실행해줍니다.
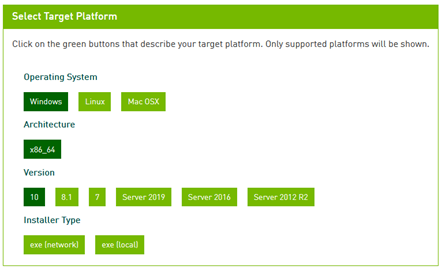
exe[network]는 네트워크에서 나눠서 다운받는것이고 exe[local]은 설치파일을 한번에 받아놓는 방식입니다.
저는 local 방식으로 설치했습니다.
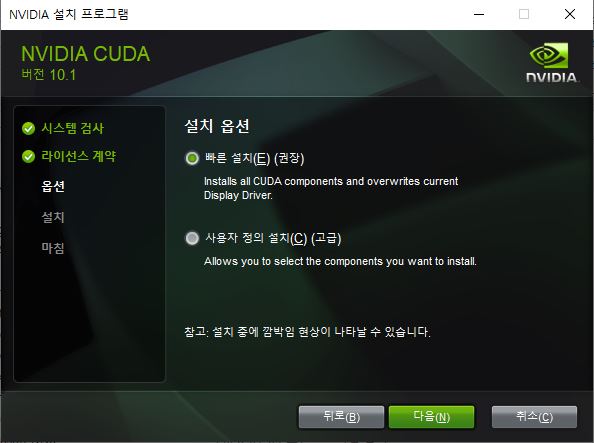
설치 옵션은 빠른 설치로 진행해줍니다.
설치된 저의 경로는 아래와 같습니다.
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1
다운로드가 완료되었으면 cuDNN을 설치합니다.
cuDNN을 다운받으려면 NVIDIA 회원가입 후 로그인 된 상태에서 가능합니다.
https://developer.nvidia.com/rdp/cudnn-archive
cuDNN Archive
NVIDIA cuDNN is a GPU-accelerated library of primitives for deep neural networks.
developer.nvidia.com

회원가입이 되셨으면 위의 사이트에 들어가서 v7.6.3 버전을 다운받아 줍니다.
위의 사진처럼 Download cuDNN v7.6.3 for CUDA 10.1 이면 10.1 버전용 cuDNN 이라는 뜻입니다.
v7.6.3 이지만 CUDA 9.0 ,10.0 , 10.1 버전 등 각자 본인에 버전에 맞는 파일이 다르기때문에 주의해서 다운받아줍시다.

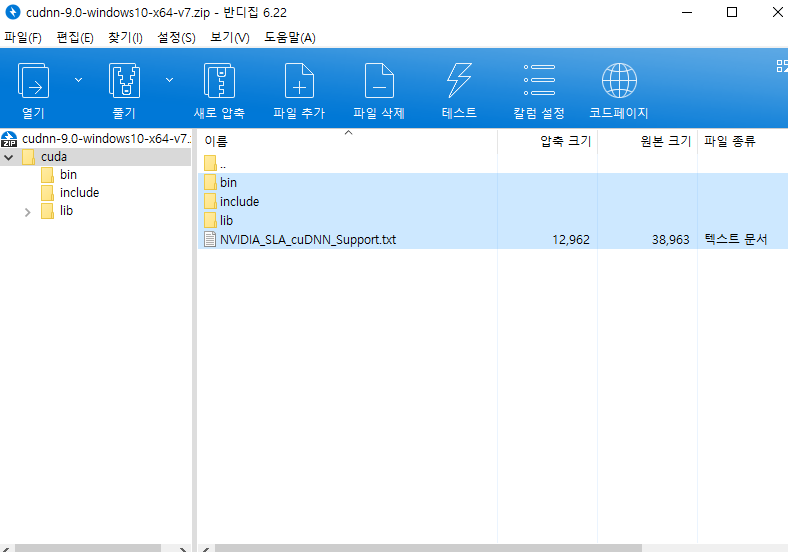
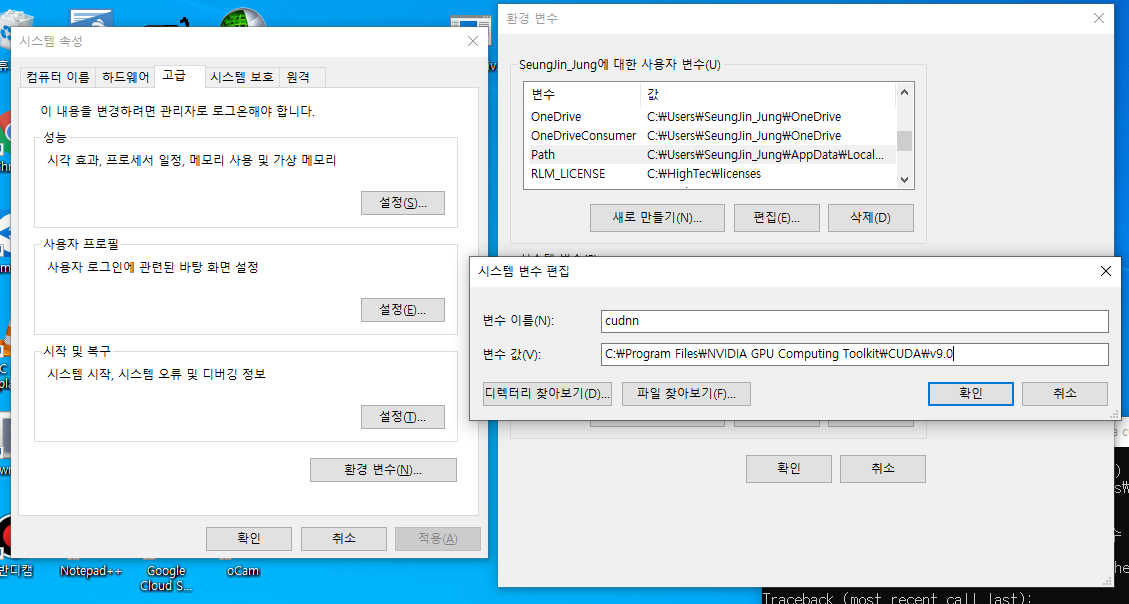
다운로드가 완료되면 폴더가 하나 있는데 저는 D드라이브에 넣어뒀습니다. 저의 cuDNN 경로는 아래와 같습니다.
D:\cuda
2. OpenCV 4.0.1 설치
https://opencv.org/releases/page/2/
Releases – Page 2
opencv.org
위의 홈페이지 들어가서 4.0.1 버전을 클릭해줍니다.
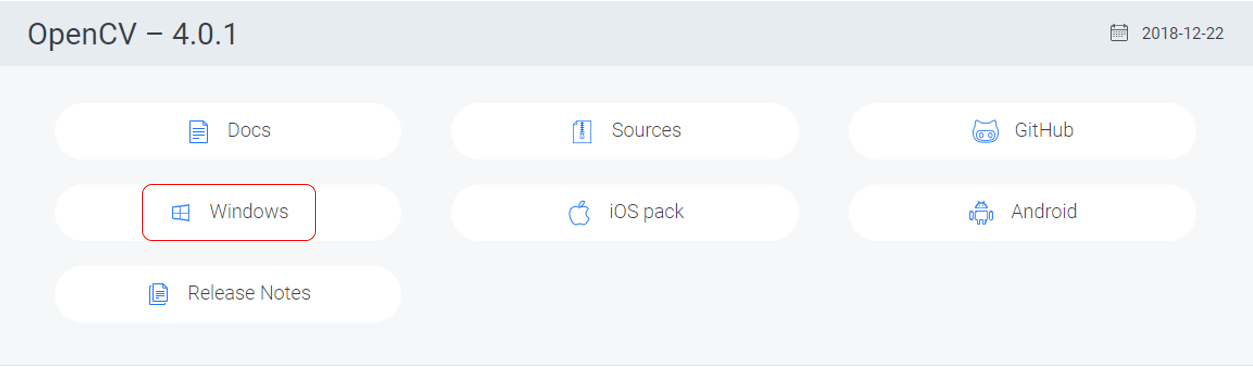
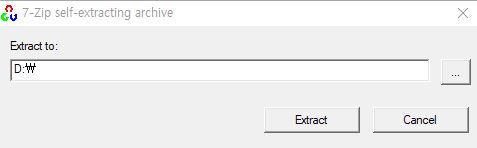
저는 D드라이브에 설치를 진행하였습니다.
3. Darknet 설치 및 환경 세팅 (중요)
파일을 받아주고 압축을 풀어줍니다.
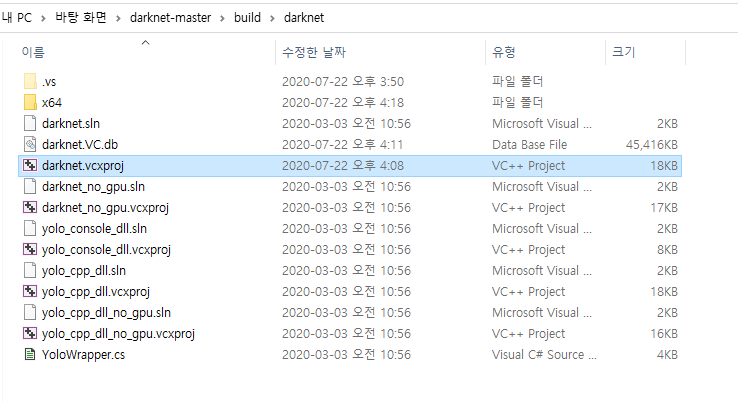
darknet-master -> build -> darknet 폴더에 들어가면 darknet.vcxproj 파일이 있습니다.
저는 편집을 편리하게 하기위해 Notepad++ 라는 프로그램을 설치하였습니다.
오른쪽 버튼 클릭을하면 Edit with Notepad++ 로 수정할 수 있습니다.

2번째 line에 본인의 Visual Studio 버전에 맞게 수정해주시면 됩니다. 저는 2015 버전을 쓰기때문에
ToolsVersion="14.0"으로 지정하였습니다.

↓

55번째 라인에
$(VCTargetsPath)\BuildCustomizations\CUDA 10.0.props을
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\extras\visual_studio_integration\MSBuildExtensions\CUDA 10.1.props로 바꿔줍니다.
마찬가지로 마지막 줄에 있는
$(VCTargetsPath)\BuildCustomizations\CUDA 10.0.props 부분도
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\extras\visual_studio_integration\MSBuildExtensions\CUDA 10.1.targets 으로 바꿔줍니다.

이제 darknet.sln 을 실행해서 프로젝트 -> 속성으로 들어가줍니다.

구성을 Release 플랫폼을 x64 로 바꿔주고 아래의 세팅을 하셔야합니다.
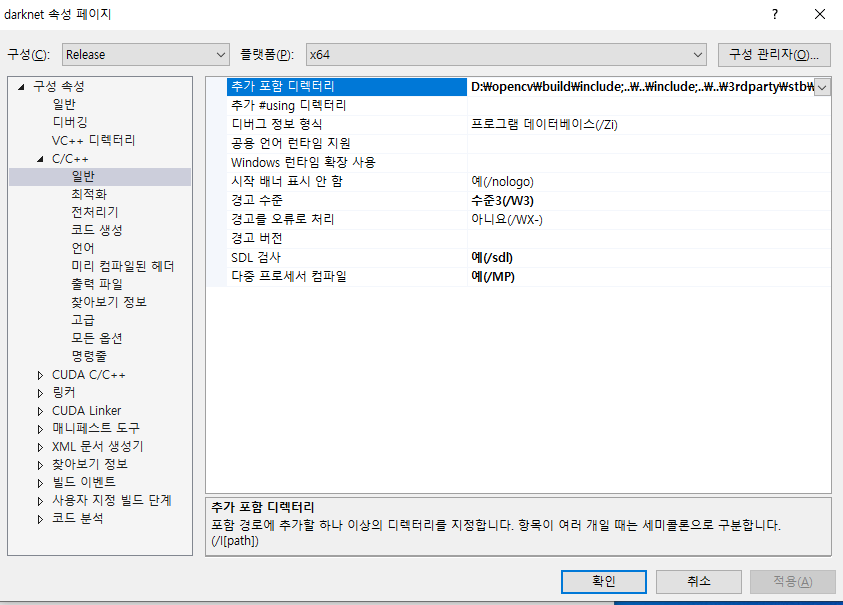
C/C++ -> 일반(general) -> 추가 포함 디렉터리(additional include directories) 을 편집해줘야 합니다.
제 기준으로 편집 전
$(OPENCV_DIR)\include;
C:\opencv_3.0\opencv\build\include;
..\..\include;
..\..\3rdparty\stb\include;
..\..\3rdparty\pthreads\include;
%(AdditionalIncludeDirectories);
$(CudaToolkitIncludeDir);
$(CUDNN)\include;
$(cudnn)\include
↓
편집 후
D:\opencv\build\include
..\..\include
..\..\3rdparty\stb\include
..\..\3rdparty\pthreads\include
%(AdditionalIncludeDirectories)
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\include
D:\cuda\include
위의 과정은 OpenCV 와 CUDA , cuDNN 의 올바른 include 경로를 설정해주는 과정입니다.

다음으로 CUDA C/C++ -> Device -> Code Generation 에서 자신의 Compute capability에 맞게 수정해줍니다.
거의다왔습니다!!
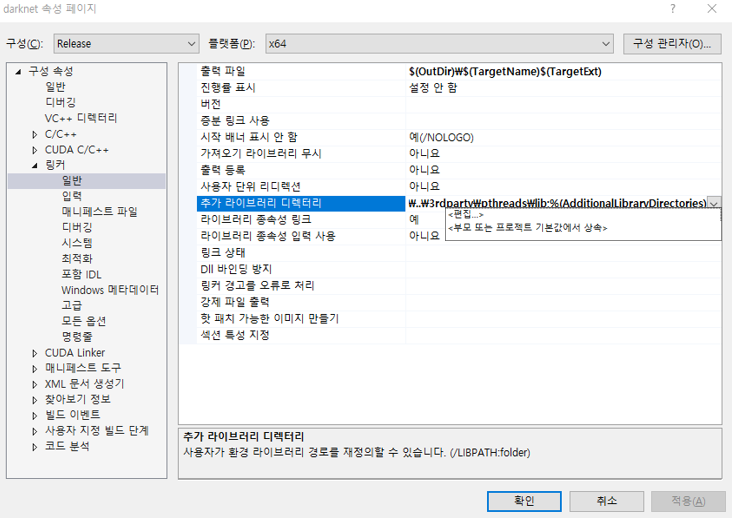
링커(Linker) -> 일반(general) -> 추가 라이브러리 디렉터리(Additional Library Directories) 를 편집해줘야 합니다.
제 기준으로 편집 전
C:\opencv_2.4.9\opencv\build\x86\vc14\lib;
C:\opencv_2.4.9\opencv\build\x86\vc12\lib;
$(CUDA_PATH)lib\$(PlatformName);
$(cudnn)\lib\x64;
..\..\3rdparty\pthreads\lib;
%(AdditionalLibraryDirectories)
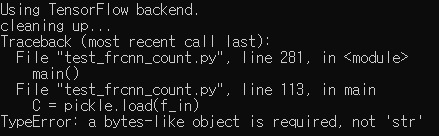
↓
D:\opencv\build\x64\vc14\lib;
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\lib\$(PlatformName);
D:\cuda\lib\x64;
..\..\3rdparty\pthreads\lib;
%(AdditionalLibraryDirectories)
편집 후입니다.
YOLO에서 CUDA와 OpenCV를 실행을 위한 dll 파일들을 옮겨줘야합니다.


C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\bin 에서
cublas64_10.dll
cudart64_101.dll
curand64_10.dll
cusolver64_10.dll
D:\opencv\build\x64\vc14\bin 에서
opencv_world401.dll
opencv_world401d.dll
opencv_ffmpeg401_64.dll
총 7개의 파일을 darknet-master\build\darknet\x64 폴더 안에 넣어줍니다.
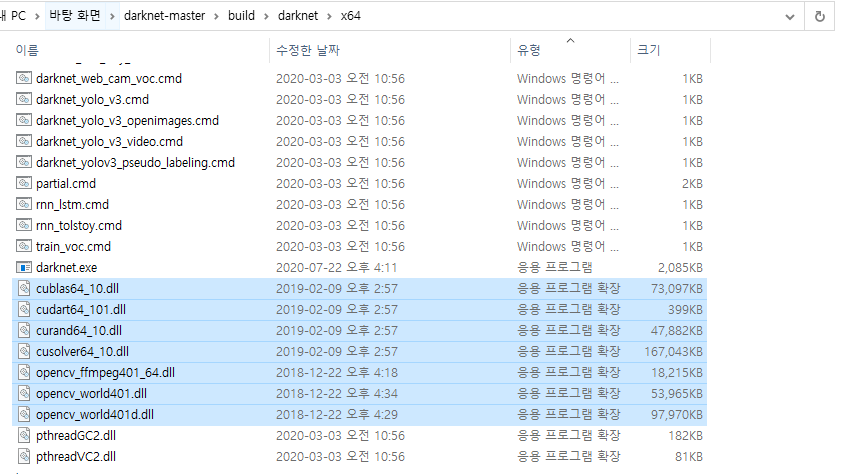
넣어주시고 다시 darknet.sln 파일을 실행시킨 후에

Release 에 x64인지 확인해 주시고 빌드(B) -> 솔루션 빌드 를 진행시켜줍니다.

휴~~ 드디어 빌드가 완료되었습니다. 성공이 되셨다면 YOLO 세팅이 정상적으로 된것입니다.
4. 간단한 예제 실행
yolov3.weights (236 MB COCO Yolo v3): https://pjreddie.com/media/files/yolov3.weights
우선 미리 훈련된 weights 파일을 다운받아서
darknet-master\build\darknet\x64 폴더안에 넣어줍니다.
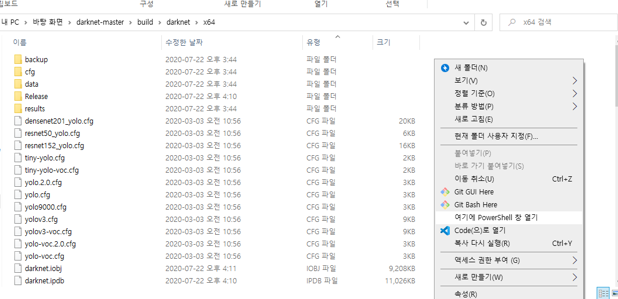
폴더에 들어가서 빈 곳에 Shift + 오른쪽버튼을 누르면 위의 사진과 같이 여기에 PowerShell 창 열기가 뜹니다.
간단한 예제를 돌려보겠습니다.
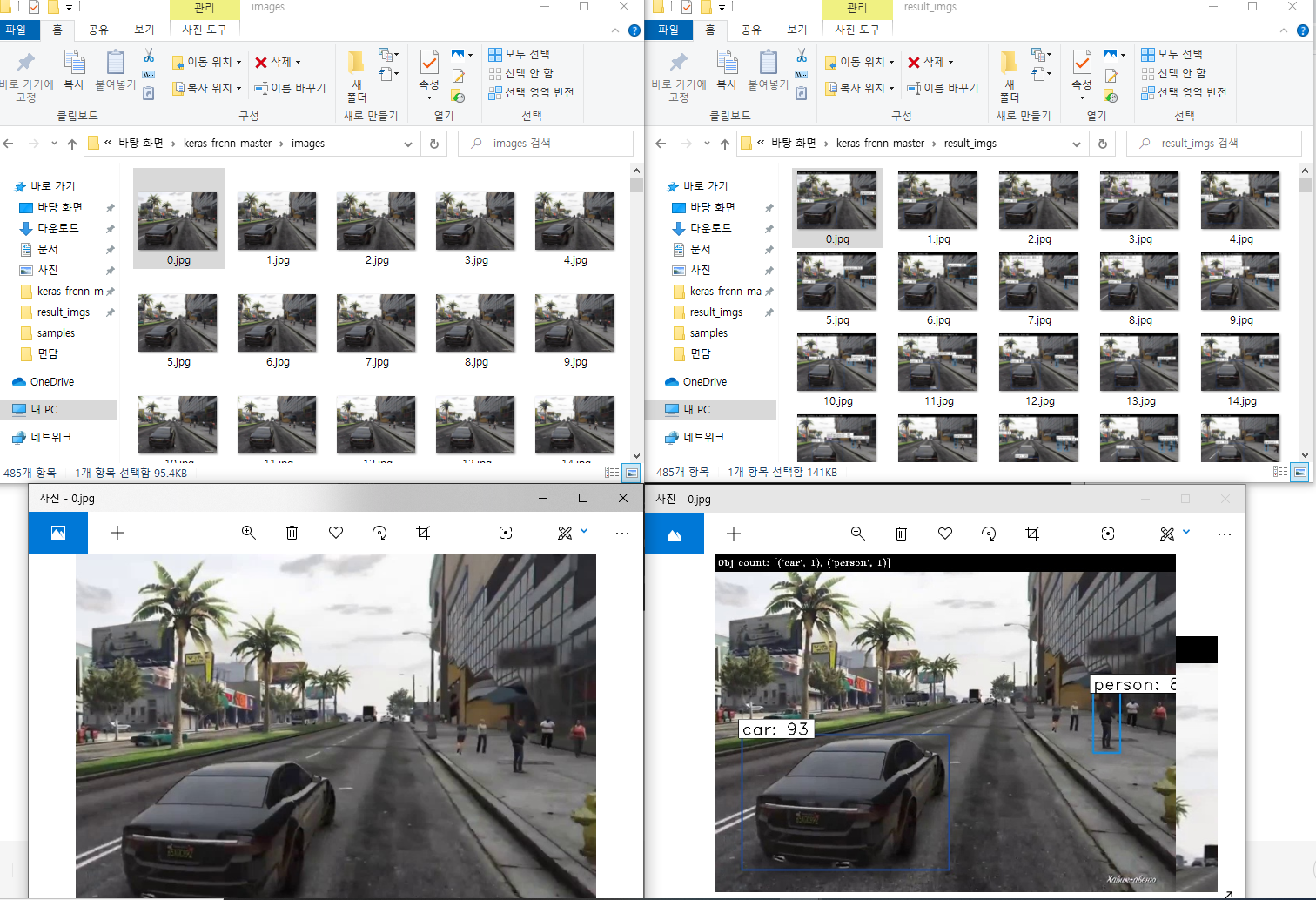
./darknet.exe detector test data/coco.data yolov3.cfg yolov3.weights data/dog.jpg


정상적으로 설치가 되어서 위와 같이 object detection 이 성공적으로 되네요~
혹시나 설치과정중에 에러가 발생하면 댓글 남겨주세요. 설치하느라 고생하셨습니다~!!
'AI > YOLO' 카테고리의 다른 글
| YOLO 학습시 cfg 파일 설정(anchors) (3) | 2020.03.20 |
|---|---|
| [Windows] 마스크 착용 유/무 판단을 위한 YOLO 학습 (78) | 2020.03.10 |