주의할 코드부분은 관심영역을 자르고 나서 원본 사진의 해상도와 맞게 resize를 시켜주었습니다.
OpenCV에서는 resize 진행시 보간법(interpolation methods)을 지정해줄 수 있습니다. 대표적으로 INTER_CUBIC ,INTER_LINEAR 등이 있습니다만, INTER_CUBIC을 사용하면 보다 더 선명한 이미지를 얻을수 있다고 합니다. 그러나 저는 INTER_LINEAR 방식으로 진행하였습니다.
히스토그램 생성
관심영역이 추출된 이미지를 가지고 본격적으로 인식에 가장 필요한 히스토그램을 생성하는 파트입니다.
히스토그램이란?
히스토그램(Histogram)은 표로 되어 있는 도수 분포를 정보 그림으로 나타낸 것입니다.
그러나 이미지 히스토그램은 이야기가 조금 다릅니다.
이미지 히스토그램은 가로축(x축) 에는 이미지의 픽셀 값을 나타내는 좌표값이고, 세로축(y축)으로는 픽셀의 수를 나타내는 좌표값입니다. 히스토그램으로 이미지의 대비(Contrast)나 빛의 강도 등을 나타낼 수도 있기 때문에, 이미지에서 어떤 특징점이 어느정도 분포하고 있는지 알 수 있는 그래프라고 볼 수 있습니다.
0과 9에대한 히스토그램... 별 차이가 없다.
저는 본 프로젝트를 진행하면서, 그레이스케일 변환한 숫자에 대해 히스토그램을이용하여 숫자 0~9 까지의 히스토그램을 모두 그려보았으나 뚜렷한 특징을 찾을 수가 없었습니다. 따라서 아래의 그림과 같이 진행하였습니다.
x축좌표에 대한 0에 해당하는 픽셀 개수를 표현
y축좌표에 대한 0에 해당하는 픽셀 개수를 표현
가로, 세로 축 좌표를 기준으로 숫자의 픽셀(검정색)의 개수를 카운팅하여, 빈 검정색 이미지에 line함수로 픽셀의 개수만큼 그려주었습니다. 축의 기준을 나눠서 히스토그램을 생성한 이유는 기존 히스토그램 사용시에, 밝은 픽셀과 어두운 픽셀의 분포를 표시하기 때문에 입력되는 이미지의 숫자의 크기에 따라 오인식 하는 확률이 크기 때문에 위와 같이 진행했었습니다.
x축 좌표에 대한 히스토그램 을 보면 가로축은 x가 0부터 image의 rows까지 , 세로축은 픽셀의 개수를 나타내었고
y축 좌표에 대한 히스토그램 역시 보면 가로축은 y가 0부터 image의 cols까지, 세로축은 픽셀의 개수를 나타내었습니다.
/************************** ROI 좌표 찾기 *****************************/
roi_image = binary_image(Rect(Point(x_min, y_min), Point(x_max, y_max)));
resize(roi_image, roi_image, Size(200, 200), 0, 0, INTER_LINEAR);
Mat x_hist_image = Mat::zeros(roi_image.rows, roi_image.cols, CV_8U);
Mat y_hist_image = Mat::zeros(roi_image.rows, roi_image.cols, CV_8U);
Mat total_hist_image = Mat::zeros(roi_image.cols, roi_image.rows * 2, CV_8U);
/************************** histogram ****************************/
for (int y = 0; y < roi_image.rows; y++) //y축 히스토그램
{
pixel_count = 0;
for (int x = 0; x < roi_image.cols; x++)
{
if (roi_image.at<uchar>(x, y) == 0)
{
pixel_count++;
}
}
y_count[y] = pixel_count;
}
for (int x = 0; x < roi_image.cols; x++) //x축 히스토그램
{
pixel_count = 0;
for (int y = 0; y < roi_image.rows; y++)
{
if (roi_image.at<uchar>(x, y) == 0)
{
pixel_count++;
}
}
x_count[x] = pixel_count;
}
for (int x = 0; x < roi_image.rows; x++) //x축 히스토그램 그리기
line(x_hist_image, Point(x, roi_image.rows), Point(x, roi_image.rows - x_count[x]), Scalar(255, 255, 255), 0);
for (int y = 0; y < roi_image.cols; y++) //y축 히스토그램 그리기
line(y_hist_image, Point(y, roi_image.cols), Point(y, roi_image.cols - y_count[y]), Scalar(255, 255, 255), 0);
/* 통합 히스토그램 그리기 */
for (int x= 0; x < roi_image.rows; x++)
line(total_hist_image , Point(x + 200, roi_image.rows), Point(x+200, roi_image.rows - x_count[x]), Scalar(255, 255, 255), 0);
for (int y = 0; y < roi_image.cols; y++)
line(total_hist_image, Point(y, roi_image.cols), Point(y, roi_image.cols - y_count[y]), Scalar(255, 255, 255), 0);
/************************** histogram ****************************/
imshow("x_hist", x_hist_image);
imshow("y_hist", y_hist_image);
imshow("original", original_image);
imshow("bin", binary_image);
imshow("roi_image", roi_image);
imshow("total", total_hist_image);
waitKey(0);
}
코드 중 가로 세로축 히스토그램을 그리는 코드의 일부입니다.
위의 코드 역시 이중 for문을 이용하여 이미지의 행 ,열을 훑어 연산하면서 픽셀의 카운트를 진행하였습니다.
테스트할 이미지의 데이터와 비교할 표준 숫자 데이터 0~9까지의 히스토그램을 모두 생성하여 저장하였습니다.
그림과 같이 각 숫자마다 모두 다른 히스토그램을 확인할 수 있습니다.
이제 표준 데이터의 히스토그램을 모두 저장하였으니,
테스트할 숫자 이미지 역시 지금까지 진행했던 방식으로 히스토그램을 생성합니다.
테스트할 숫자 데이터는 인터넷에서 자동차 번호판의 숫자를 찾아서 아래 그림과 같이 크기와 위치가 다르게 저장하여 진행하였습니다.
/* compare */
for (int i = 0; i < 10; i++)
{
for (int j = 0; j < 10; j++)
{
for (int y = 0; y < total_hist_image[i].cols; y++) //y축 히스토그램
{
for (int x = 0; x < total_hist_image[i].rows; x++)
{
if (total_hist_image[i].at<uchar>(x, y) != test_total_hist_image[j].at<uchar>(x, y))
test_check_sum[i]++;
}
}
if (check_sum[i] <= min)
min = test_check_sum[i];
}
if (test_check_sum[i] == min)
min = i;
detect_num[i] = min;
}
/* compare */
표준 히스토그램 데이터와의 픽셀차이를 계산하는 코드중 일부입니다.
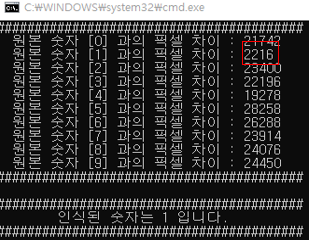
본 코드가 관심영역 추출이 올바르게 되는지, 글자의 크기에 영향을 미치지 않는지 테스트를 진행해보았습니다.
테스트할 숫자 이미지가 입력이 되면 표준 숫자 데이터 0~9 를 각각 비교하면서 픽셀차이가 가장 적은 숫자를
인식하는 숫자로 판정하였습니다. 위의 사진과 같이 똑같은 글꼴이지만 위치와 숫자의 크기를 달리 하여도 표준 히스토그램의 특징과 뚜렷하게 다른점이 거의 없습니다.
테스트 숫자의 픽셀이 관심영역을 추출하면서 resize되어
글꼴이 깨져도 숫자의 본 모습은 크게 바뀌지 않아서 그런것 같습니다.
한계점..
ㄴ
본 프로젝트에서 진행한 숫자인식 방법은 가로 세로축을 기준으로 픽셀의 개수를 측정하였기 때문에 숫자가 조금만 회전이 되어도 오인식 하는 경우가 많았습니다..
회전이나 글꼴 차이에 해당하는 경우의 수는 고려하지 않고 반영하였기 때문에 본프로젝트는 추후에 더욱 좋은 구상을 통해 보완해야할 것 같습니다. 추후에 더욱 좋은 구상을 통해 보완하게 된다면 비교적 무거운 딥러닝을 사용하지 않고도 자동차 번호판을 인식할 수 있는 프로그램을 만들 수 있기 때문에 제한된 하드웨어 성능내에서 효율적인 시스템을 만들수 있을 것 같습니다.
본 프로젝트는 자동차 번호판 숫자 인식을 위한 프로젝트의 일부로 진행하였습니다.
막상 딥러닝을 이용할때는 몰랐는데 딥러닝의 필요성을 알게되는 프로젝트 중 하나였습니다. 영상처리에 대한 공부를 진행하면서 숫자 인식을 위해 진행했던 부분들이 흥미로운점이 많았던 것 같습니다.