안녕하세요. 요새 코로나도 심해지는 와중에 건강 조심하시기 바랍니다.
집에서 코딩하는 것을 추천드려요~
이번 게시물에서는 딥러닝을 이용하지 않고
OpenCV를 이용하여 자동차 번호판 글꼴의 숫자를 인식하는 프로젝트를 작성합니다.
아직 자동차 번호판을 곧바로 인식하기엔 어려움이 있기 때문에 자동차 번호판의 숫자 글꼴을 인식하는 프로젝트로 진행하였습니다.
딥러닝을 이용해보신적이 있으시다면 숫자인식은 어떻게보면 "Hello World"같은 예제일정도로 쉬운 일입니다.
숫자나 어떤 이미지를 인식한다고 하면, 딥러닝에서는 데이터에서 특징을 추출하여 학습을 하여 인식을합니다.
그러나 OpenCV 라이브러리만을 이용하여 인식한다면 꽤나 생각해야할 부분이 많습니다..
본 게시물에서 진행한 숫자인식은 이런방법으로도 접근할 수 있구나라고 생각하고 봐주시면 감사하겠습니다.
제가 진행한 프로젝트의 흐름도는 다음과 같습니다.

우선 간단하게 요약하자면 숫자인식을 하기 위해 이미지 전처리, 관심영역 추출, 히스토그램 생성의 과정을 거칩니다.
표준 숫자 0~9 까지에 대해 위의 세과정을 거쳐서 표본을 만든후에
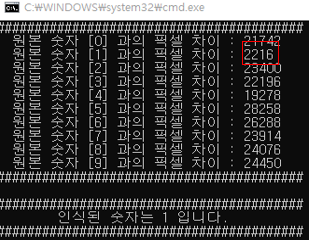
테스트할 숫자를 넣어 위와 같은 과정을 거쳐 표본 히스토그램의 픽셀수와 테스트 이미지 히스토그램의 픽셀수를 비교하여 가장 적게 차이나는 히스토그램을 가진 숫자를 인식된 숫자로 판정합니다.
이미지 전처리
#define _CRT_SECURE_NO_WARNINGS
#include <opencv2/core.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/opencv.hpp>
#include <iostream>
using namespace std;
using namespace cv;
int main()
{
Mat original_image; //image read(grayscale)
Mat binary_image; //binary image
original_image = imread("1.jpg", IMREAD_GRAYSCALE); //grayscale
threshold(original_image, binary_image, 127, 255, THRESH_BINARY); //threshold
imshow("grayscale", original_image);
imshow("binary", binary_image);
waitKey(0);
}OpenCV를 이용하면 간단하게 이미지를 불러와서 그레이스케일 변환과 이진화를 진행할 수 있습니다.

이진화를 진행할때 threshold 값을 정해주어야 합니다. 그림에서 보이는 것과 같이 0이라는 숫자에
이미지의 quality가 좋지않아 noise가 발생되어있는데 0과 255 두개로만 픽셀을 깔끔하게 표현하기 위해서는
0의 윤곽쪽을 제외하고는 모두 255(흰색)으로 만들어줍니다.

입력된 기본 original image를 그레이스케일 변환과 이진화를 진행한 사진입니다.
컬러 이미지를 흑백으로 전환하여 1채널(0~255)의 값으로 변경후 숫자 이미지의 픽셀을 0과 255로만 이루어지게 이진화를 거쳐 연산에 효율성과 인식율을 향상할 수 있었습니다.
이렇게 전처리를 진행함으로써 이미지의 픽셀에 접근하여 연산하는 과정 및 픽셀을 확인하는 과정을 효율적으로
진행할 수 있습니다.
관심 영역 추출
이제 이진화까지의 과정을 거쳐서 0과 255로만 구성된 이미지를 얻었습니다.
다음 단계는 숫자 이외의 불필요한 배경들을 제거하여 숫자의 해당하는 픽셀의 연산에 조금더 정확하고 효율적으로
진행할 수 있도록 관심 영역의 x축 최소,최대 y축 최소,최대 좌표를 구하여 자르는 과정입니다.
아래의 그림을 보면 이해가 쉽게 될 것 같습니다.

그림의 가로축을 X, 세로축 Y으로 놓았을때 좌측 상하단 우측 상하단을 순차적으로 돌면서 0의 라인에 해당하는
최솟값 최대값을 찾아냅니다. X-MIN ,X-MAX, Y-MIN , Y-MAX 값만 찾아내면 그값을 기준으로 자르면 되니까요.
#define _CRT_SECURE_NO_WARNINGS
#include <opencv2/core.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/opencv.hpp>
#include <iostream>
using namespace std;
using namespace cv;
int main()
{
Mat original_image; //image read
Mat binary_image; //binary image
Mat roi_image; //roi image
int x_count[200] = { 0, };
int y_count[200] = { 0, };
int x_min = 0, x_max = 0, y_min = 0, y_max = 0;
int status = 0, pixel_count = 0;
original_image = imread("0.jpg", IMREAD_GRAYSCALE); //grayscale
threshold(original_image, binary_image, 127, 255, THRESH_BINARY); //threshold
/************************** ROI 좌표 찾기 *****************************/
for (int x = 0; x < binary_image.rows; x++) //x좌표 최솟값
{
for (int y = 0; y < binary_image.cols; y++)
{
if (binary_image.at<uchar>(y, x) == 0)
{
x_min = x;
status = 1;
break;
}
if (status == 1)
break;
}
}
status = 0;
for (int y = binary_image.cols - 1; y >= 0; y--) //x좌표 최댓값
{
for (int x = binary_image.rows - 1; x >= 0; x--)
{
if (binary_image.at<uchar>(y, x) == 0)
{
x_max = x;
y_max = y;
status = 1;
break;
}
if (status == 1)
break;
}
}
status = 0;
for (int y = 0; y < binary_image.cols; y++) //y좌표 최솟값
{
for (int x = 0; x < binary_image.rows; x++)
{
if (binary_image.at<uchar>(y, x) == 0)
{
y_min = y;
status = 1;
break;
}
if (status == 1)
break;
}
}
status = 0;
for (int x = binary_image.rows - 1; x >= 0; x--) //y좌표 최댓값
{
for (int y = binary_image.cols - 1; y >= 0; y--)
{
if (binary_image.at<uchar>(y, x) == 0)
{
if (y >= y_max)
y_max = y;
if (x >= x_max)
x_max = x;
status = 1;
break;
}
if (status == 1)
break;
}
}
status = 0;
/************************** ROI 좌표 찾기 *****************************/
roi_image = binary_image(Rect(Point(x_min, y_min), Point(x_max, y_max)));
resize(roi_image, roi_image, Size(200, 200), 0, 0, INTER_LINEAR);
rectangle(binary_image, Rect(Point(x_min, y_min), Point(x_max, y_max)), Scalar(0, 0, 100), 1, 4, 0);
imshow("original", original_image);
imshow("bin", binary_image);
imshow("roi_image", roi_image);
waitKey(0);
}

위의 코드를 숫자 0을 입력하여 얻은 이미지입니다.
좌표가 올바르게 찾아졌는지 rectangle 함수를 이용하여 관심영역에 사각형을 그려보았습니다.
좌상하단 , 우상하단 = 4번의 연산이 필요합니다.
이중 for문을 이용하여 간단하게(?) 구현할 수 있습니다.
좌표를 찾았을때 break문을 걸어 탈출하며 flag를 바꾸는 방식으로 구현해보았습니다.
사실 코딩실력이 좋은편이 아니기 때문에 다소 난잡할 수 있으나,
구현적인 측면도 중요했기 떄문에 코드가 난잡하더라도 귀엽게 주니어 개발자를 봐주시면 감사하겠습니다.
roi_image = binary_image(Rect(Point(x_min, y_min), Point(x_max, y_max)));
resize(roi_image, roi_image, Size(200, 200), 0, 0, INTER_LINEAR);
주의할 코드부분은 관심영역을 자르고 나서 원본 사진의 해상도와 맞게 resize를 시켜주었습니다.
OpenCV에서는 resize 진행시 보간법(interpolation methods)을 지정해줄 수 있습니다.
대표적으로 INTER_CUBIC ,INTER_LINEAR 등이 있습니다만, INTER_CUBIC을 사용하면 보다 더 선명한 이미지를 얻을수 있다고 합니다. 그러나 저는 INTER_LINEAR 방식으로 진행하였습니다.
히스토그램 생성
관심영역이 추출된 이미지를 가지고 본격적으로 인식에 가장 필요한 히스토그램을 생성하는 파트입니다.
히스토그램이란?
히스토그램(Histogram)은 표로 되어 있는 도수 분포를 정보 그림으로 나타낸 것입니다.
그러나 이미지 히스토그램은 이야기가 조금 다릅니다.
이미지 히스토그램은 가로축(x축) 에는 이미지의 픽셀 값을 나타내는 좌표값이고, 세로축(y축)으로는 픽셀의 수를 나타내는 좌표값입니다. 히스토그램으로 이미지의 대비(Contrast)나 빛의 강도 등을 나타낼 수도 있기 때문에, 이미지에서 어떤 특징점이 어느정도 분포하고 있는지 알 수 있는 그래프라고 볼 수 있습니다.

저는 본 프로젝트를 진행하면서, 그레이스케일 변환한 숫자에 대해 히스토그램을이용하여 숫자 0~9 까지의 히스토그램을 모두 그려보았으나 뚜렷한 특징을 찾을 수가 없었습니다. 따라서 아래의 그림과 같이 진행하였습니다.


가로, 세로 축 좌표를 기준으로 숫자의 픽셀(검정색)의 개수를 카운팅하여, 빈 검정색 이미지에 line함수로 픽셀의 개수만큼 그려주었습니다. 축의 기준을 나눠서 히스토그램을 생성한 이유는 기존 히스토그램 사용시에, 밝은 픽셀과 어두운 픽셀의 분포를 표시하기 때문에 입력되는 이미지의 숫자의 크기에 따라 오인식 하는 확률이 크기 때문에 위와 같이 진행했었습니다.
x축 좌표에 대한 히스토그램 을 보면 가로축은 x가 0부터 image의 rows까지 , 세로축은 픽셀의 개수를 나타내었고
y축 좌표에 대한 히스토그램 역시 보면 가로축은 y가 0부터 image의 cols까지, 세로축은 픽셀의 개수를 나타내었습니다.
/************************** ROI 좌표 찾기 *****************************/
roi_image = binary_image(Rect(Point(x_min, y_min), Point(x_max, y_max)));
resize(roi_image, roi_image, Size(200, 200), 0, 0, INTER_LINEAR);
Mat x_hist_image = Mat::zeros(roi_image.rows, roi_image.cols, CV_8U);
Mat y_hist_image = Mat::zeros(roi_image.rows, roi_image.cols, CV_8U);
Mat total_hist_image = Mat::zeros(roi_image.cols, roi_image.rows * 2, CV_8U);
/************************** histogram ****************************/
for (int y = 0; y < roi_image.rows; y++) //y축 히스토그램
{
pixel_count = 0;
for (int x = 0; x < roi_image.cols; x++)
{
if (roi_image.at<uchar>(x, y) == 0)
{
pixel_count++;
}
}
y_count[y] = pixel_count;
}
for (int x = 0; x < roi_image.cols; x++) //x축 히스토그램
{
pixel_count = 0;
for (int y = 0; y < roi_image.rows; y++)
{
if (roi_image.at<uchar>(x, y) == 0)
{
pixel_count++;
}
}
x_count[x] = pixel_count;
}
for (int x = 0; x < roi_image.rows; x++) //x축 히스토그램 그리기
line(x_hist_image, Point(x, roi_image.rows), Point(x, roi_image.rows - x_count[x]), Scalar(255, 255, 255), 0);
for (int y = 0; y < roi_image.cols; y++) //y축 히스토그램 그리기
line(y_hist_image, Point(y, roi_image.cols), Point(y, roi_image.cols - y_count[y]), Scalar(255, 255, 255), 0);
/* 통합 히스토그램 그리기 */
for (int x= 0; x < roi_image.rows; x++)
line(total_hist_image , Point(x + 200, roi_image.rows), Point(x+200, roi_image.rows - x_count[x]), Scalar(255, 255, 255), 0);
for (int y = 0; y < roi_image.cols; y++)
line(total_hist_image, Point(y, roi_image.cols), Point(y, roi_image.cols - y_count[y]), Scalar(255, 255, 255), 0);
/************************** histogram ****************************/
imshow("x_hist", x_hist_image);
imshow("y_hist", y_hist_image);
imshow("original", original_image);
imshow("bin", binary_image);
imshow("roi_image", roi_image);
imshow("total", total_hist_image);
waitKey(0);
}코드 중 가로 세로축 히스토그램을 그리는 코드의 일부입니다.
위의 코드 역시 이중 for문을 이용하여 이미지의 행 ,열을 훑어 연산하면서 픽셀의 카운트를 진행하였습니다.
테스트할 이미지의 데이터와 비교할 표준 숫자 데이터 0~9까지의 히스토그램을 모두 생성하여 저장하였습니다.

그림과 같이 각 숫자마다 모두 다른 히스토그램을 확인할 수 있습니다.
이제 표준 데이터의 히스토그램을 모두 저장하였으니,
테스트할 숫자 이미지 역시 지금까지 진행했던 방식으로 히스토그램을 생성합니다.
테스트할 숫자 데이터는 인터넷에서 자동차 번호판의 숫자를 찾아서 아래 그림과 같이 크기와 위치가 다르게 저장하여 진행하였습니다.
/* compare */
for (int i = 0; i < 10; i++)
{
for (int j = 0; j < 10; j++)
{
for (int y = 0; y < total_hist_image[i].cols; y++) //y축 히스토그램
{
for (int x = 0; x < total_hist_image[i].rows; x++)
{
if (total_hist_image[i].at<uchar>(x, y) != test_total_hist_image[j].at<uchar>(x, y))
test_check_sum[i]++;
}
}
if (check_sum[i] <= min)
min = test_check_sum[i];
}
if (test_check_sum[i] == min)
min = i;
detect_num[i] = min;
}
/* compare */표준 히스토그램 데이터와의 픽셀차이를 계산하는 코드중 일부입니다.

본 코드가 관심영역 추출이 올바르게 되는지, 글자의 크기에 영향을 미치지 않는지 테스트를 진행해보았습니다.

테스트할 숫자 이미지가 입력이 되면 표준 숫자 데이터 0~9 를 각각 비교하면서 픽셀차이가 가장 적은 숫자를
인식하는 숫자로 판정하였습니다. 위의 사진과 같이 똑같은 글꼴이지만 위치와 숫자의 크기를 달리 하여도 표준 히스토그램의 특징과 뚜렷하게 다른점이 거의 없습니다.
테스트 숫자의 픽셀이 관심영역을 추출하면서 resize되어
글꼴이 깨져도 숫자의 본 모습은 크게 바뀌지 않아서 그런것 같습니다.
한계점..
ㄴ

본 프로젝트에서 진행한 숫자인식 방법은 가로 세로축을 기준으로 픽셀의 개수를 측정하였기 때문에 숫자가 조금만 회전이 되어도 오인식 하는 경우가 많았습니다..
회전이나 글꼴 차이에 해당하는 경우의 수는 고려하지 않고 반영하였기 때문에 본프로젝트는 추후에 더욱 좋은 구상을 통해 보완해야할 것 같습니다. 추후에 더욱 좋은 구상을 통해 보완하게 된다면 비교적 무거운 딥러닝을 사용하지 않고도 자동차 번호판을 인식할 수 있는 프로그램을 만들 수 있기 때문에 제한된 하드웨어 성능내에서 효율적인 시스템을 만들수 있을 것 같습니다.
본 프로젝트는 자동차 번호판 숫자 인식을 위한 프로젝트의 일부로 진행하였습니다.
막상 딥러닝을 이용할때는 몰랐는데 딥러닝의 필요성을 알게되는 프로젝트 중 하나였습니다. 영상처리에 대한 공부를 진행하면서 숫자 인식을 위해 진행했던 부분들이 흥미로운점이 많았던 것 같습니다.
긴 게시물 읽어주셔서 감사합니다.
'개인 프로젝트' 카테고리의 다른 글
| [MFC] MFC를 활용한 카카오톡 단체 전송 프로그램 구현 (4) | 2021.03.26 |
|---|---|
| [YOLO]COVID-19 : 마스크 착용시에만 출입가능한 시스템 구현 (118) | 2020.03.11 |
| [TCP/IP] 라즈베리파이 에서 윈도우로 문자 전송하기 (2) | 2020.03.10 |
| YOLO 와 Raspberry Pi를 이용한 출입알림시스템 (demo) (16) | 2020.02.25 |